Cosine Similarity Between Industries
Cosine Similarity Between Industries
A cosine similarity between a pair of industries is a normalized dot product. The dot product of the vector of areal employment for industry and industry is the -th, -th element of the matrix where is the matrix (data) of employment by area. This is given by:
For a graphical representation of , , and their product, see the right side of Figure 1. The lower plots show the product of employment levels, with the grid demarcating the modeled areas . The exercise in this section is to compare a normalized volume under the function in the lower left plot to the normalized area-based product in the lower right plot.
Comparing Dot Products and Density Functions
Can the dot product between two industries expressed in their areal values be compared to the overlap of their density functions? Expressed from the density functions of individual plants, this is:
This sum will potentially consist of terms, as the density function around each location can have a non-negative overlap with all other locations. Distributing the product of these sums and because of the additivity of integrals:
This can be separated into sums for each area, where the terms involving a firm in area are assigned to such area.
Comparing Areal Terms
Now let us compare the contribution of the areal terms, both in the discrete and in the continuous case. We aim to establish a relation of the type:
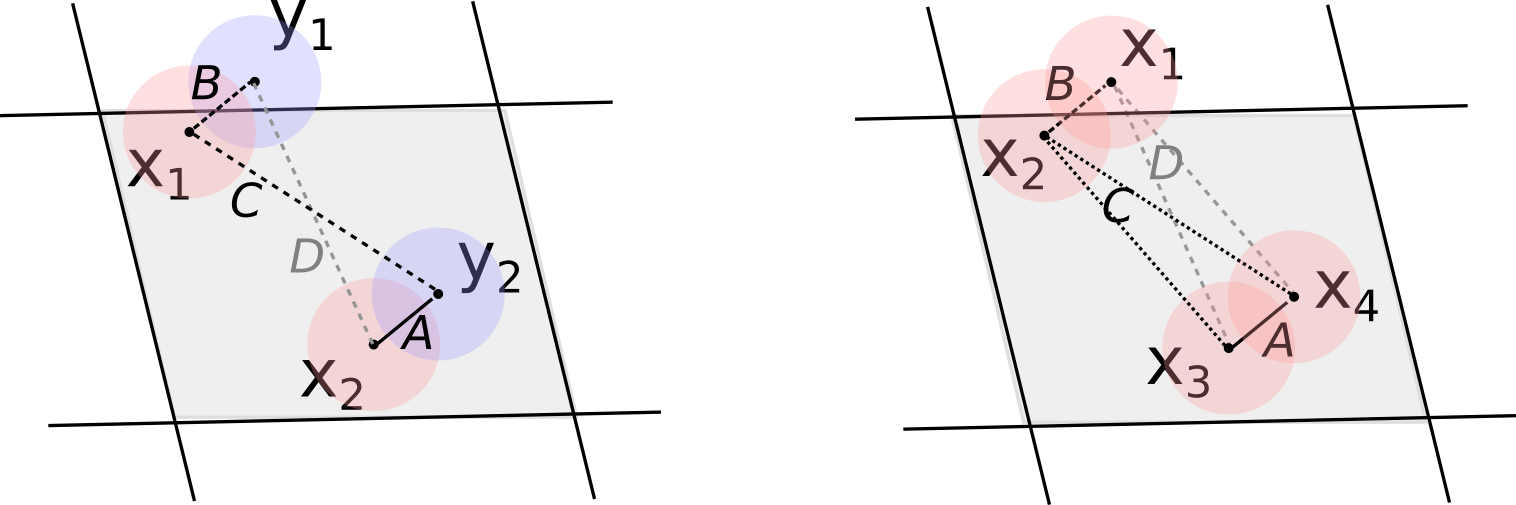
For managing this, we will distinguish four possible situations that apply to each of these pairs of , locations:
- A: The pair overlaps and shares the area.
- B: The pair overlaps while belonging to different areas.
- C: The pair does not overlap, but they belong to the same area.
- D: The pair does not overlap and they belong to different areas.
This is illustrated schematically in Figure 2.
Analyzing Pairwise Relations
Splitting the pairwise relations like this allows us to relate the individual terms of pairs when they fall in condition A, letting us move a step further. The cases in B and C introduce differences between the continuous and discrete accounts. These are the situations sometimes raised in criticism of the use of areal data and in the discussion of the MAUP problem. Namely, points can be close to each other and lie in different areas, and points can lie in the same area while being far from each other in practice. Separating these terms allows us to find out in which cases they will become small enough for the terms in A to dominate the relation. The pairs in D contribute to the agreement between the continuous and discrete accounts.
Expressing the relation split according to these cases, we have:
These expressions will match each other if the terms in the first sum match for each and the sums over cases B and C are relatively small.
For the terms from pairs in C to not dominate those in A, we need areas to not be much larger than the radius of influence of a location. For the pairs in B to not dominate those in A, we need that locations from a given area do not overlap with locations from neighboring areas, which will be the case if the radius of influence is not much larger than the area itself. Therefore, these differences between the discrete and the continuous account will be relatively smaller if the area of influence we model around the locations is about the size of the typical administrative area, not much smaller, not much larger.
As for the terms in A, the sums will be equal if each of the terms in them are equal. That is, we ask that:
Conclusion
Understanding these conditions helps in determining when the discrete and continuous models align, thus providing insights into the effective use of areal data in industry analysis.