A Convenient Framework for Working with Location Quotient Values
A Convenient Framework for Working with Location Quotient Values
In this section, we introduce useful variables for describing any observed location quotient value. We will then discuss the empirical distribution of observations in three examples: exports by country and product, patent applications by region and technology class, and business counts by city and industry.
The 2D Space for Log Location Quotients
Location quotients are defined as:
where is the value associated with categories , . The terms , , and represent the sizes of entities , , and the table total, respectively. This shows that is the ratio between the relative size of element on column and the relative size of row in the matrix total.
When , we have:
Many studies classify observations by whether they are above or below the threshold, transforming LQ levels into a binary variable .
The terms in the definition can be rearranged as:
Taking the logarithm of this definition converts the ratio to a difference:
Here, is determined by two magnitudes: (observation) and (uncorrelated margins expectation).
The definition of can be seen as a constraint involving three unknowns, lying on a two-dimensional plane. A location quotient observation is fully determined if we have two of the following: , , or .
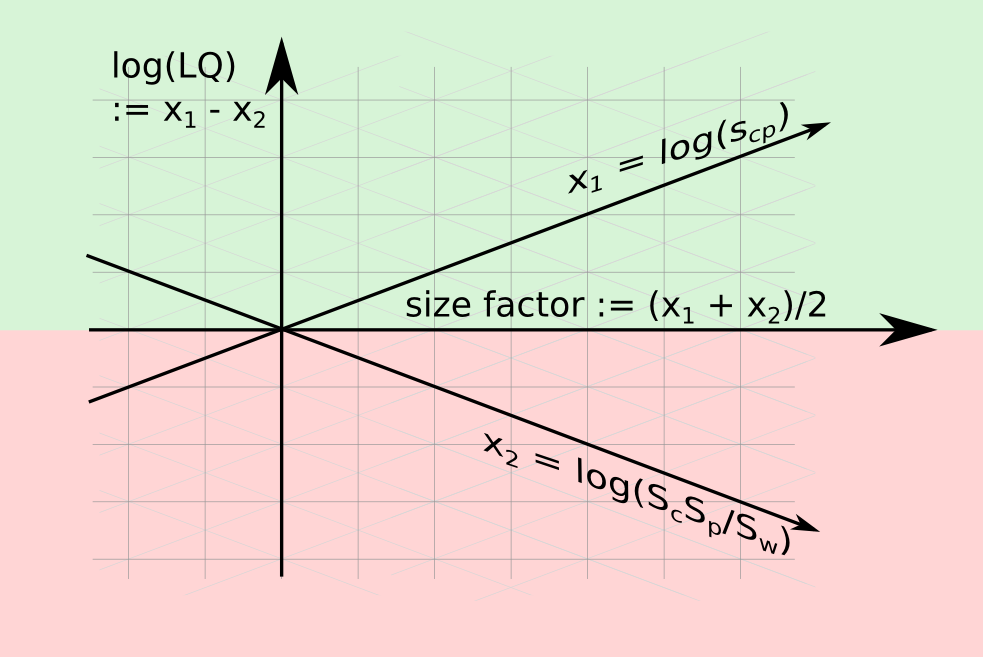
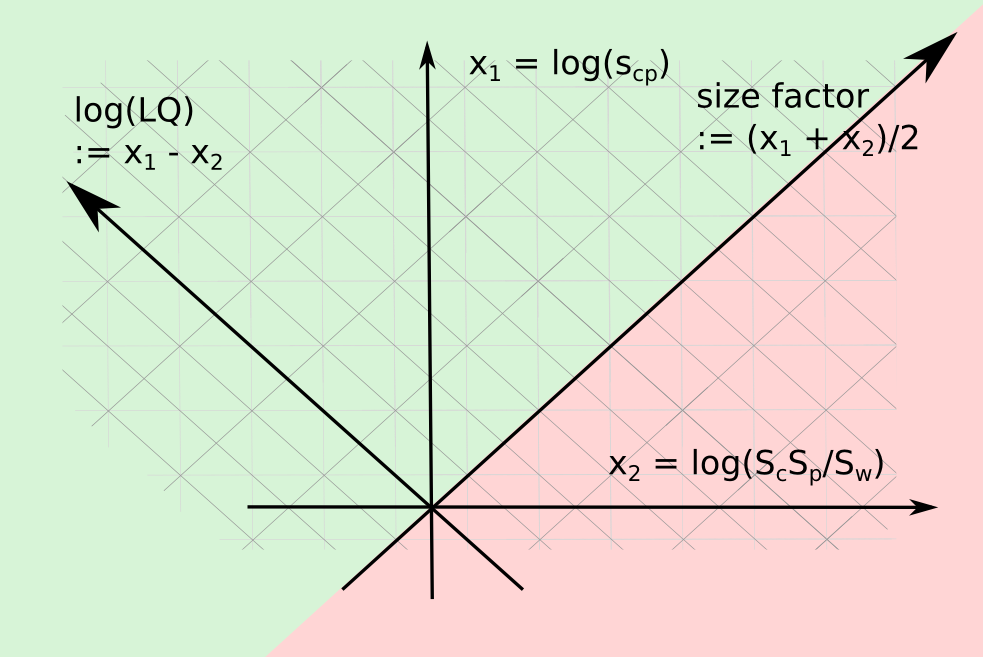
Another convenient variable is , the mean between the log observed value and the log independent margins expectation . This is called the size factor. While the location quotient captures the difference between and , the size factor captures the value around which these are situated.
Any pair in , , , is enough to define an LQ observation. These variables are linearly independent among themselves. LQ and size factor capture the asymmetric and symmetric parts of the relation between the observation and the expectation . At the threshold , the size factor matches the value that the observation and the expectation (, ) are taking.
We can describe an LQ observation using any pair of variables. In this paper, both coordinates (, ) and (, ) are used. In the first case, values are in the (green) upper hemisphere. In the second case, appear in the (green) hemisphere above the identity line, where .
This framework is useful for modeling jumps of over a threshold and dealing formally with issues involving location quotients. It helps analyze sparseness in the data, focusing on entity sizes (, , ) reflected in . The framework can be generalized to separate entity sizes: . It complements discussions on location quotients with entity sizes and absolute levels , as seen in works by Kemeny and Fracasso.
In summary, this framework is robust and convenient for formalizing questions involving location quotients.