Observations in the LQ Problem
Let us now extend the reasoning to a description of observations in terms of the pair of variables and that span the 2D space for the LQ problem. Points in these coordinates are denoted as . The two-dimensional distribution of growth rates of these coordinates is denoted as , and the region where is the two-dimensional plane region where , i.e., LQ > 1. The growth cases resulting in the condition LQ > 1 are, in calculus notation:
This integration would be approximated numerically. A practical way to do so is to store the 2D distribution of growth out of the coordinates in an array G and the condition in another array C of the same shape. In this notation, the numerical integration can simply be:
Before continuing with the strategy for estimation of two-dimensional growth probabilities G, let me emphasize that here we are propagating the volatility of observations and totals into volatility of LQ values.
Volatility and Growth Distributions
First, note that the growth rates of are essentially proportional to the standard deviation . This is larger for smaller entities, but we need to propagate this to the volatility of LQ values to conclude that smaller entities have higher jumps. Working with two-dimensional growth distributions as previously described addresses this generally. However, one can take variance in the definition :
In empirical settings, jumps in these two terms are largely independent, meaning , so:
Volatility Decay with Size
It turns out that and are functions of and , respectively. These volatilities are plotted in Figure 1. Larger nominal values fluctuate less in relative terms than smaller values, consistent with findings from Stanley et al. and others studying volatility decay with size. This dependence means that is a function of , i.e., the sizes.
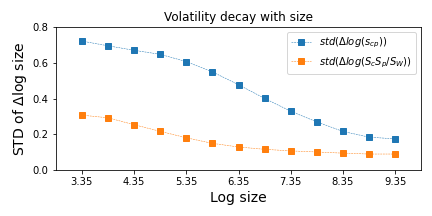
Volatility versus size. Larger observations fluctuate less and are less likely to traverse a given gap in LQ levels. The standard deviation in these plots is the width of the axis of ellipses in the subsequent figures.
Ellipse Representation of Volatility
This expression of volatility of is linked to equations of ellipses. Using the notation for variances of the jumps (), recall the equation of an ellipse centered at the origin is where , are the semi-minor and major axes, and is a measure of ellipse size. Associating the ellipse axes with the width of jumps in , , the magnitude of jumps is determined. These are the jumps in , in the sense that . See Figure 2 for a schematic diagram.
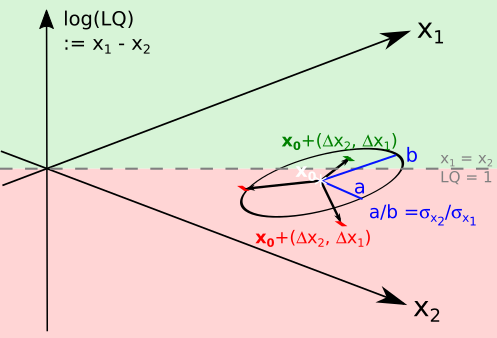
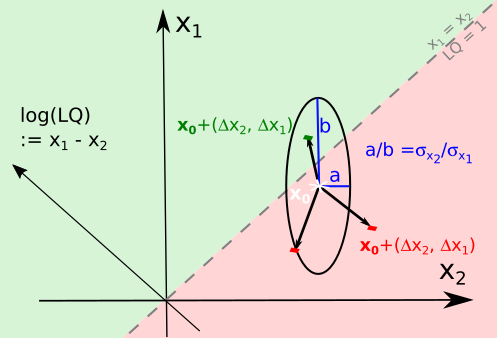
Scheme of jumps in observations after a time step. Using size factor and log(LQ) as axes (left) and observed and expected sizes as axes (right). The green regions are those where . The initial point is shown with a white star. Around it, three purported jumps after a timestep are drawn. The ellipses indicate how far jumps are expected to stretch, in the directions and and thus in any other direction given by a combination of those.
Finally, even after characterizing the widths of the jumps in , , and thus , there remains a step to translate it into chances of surpassing the threshold (pLQ). For that, let us return to our core goal of explaining pLQ by means of growth distributions. We need to count all cases where jumps have let .