The Probabilistic Location Quotient
The Probabilistic Location Quotient
In this section, we introduce the concept of a probabilistic location quotient (pLQ). This metric is defined as the probability that , given the situation at time , which is described by a point in a two-dimensional space.
Understanding pLQ
The probabilistic location quotient represents the likelihood that at time , conditional on the coordinates , defining an observation at time .
Research Context
Many studies aim to understand the likelihood of a country-product or region-technology state having . Researchers explore whether factors exist that increase the chances of transitioning from to , or vice versa. Notable works in this area include those by Hausmann, Boschma, and Neffke, among others.
The factors considered are often motivated by theory or specific research questions. The variable LQ, or its transformations such as or , is frequently included as a predictor. This inclusion is reasonable because if observations are relatively stable, is likely to be near , and the condition can be expected to persist over time.
Key Insights
When is used as the sole variable to estimate the probability that , it confirms the intuition that being above or below the threshold is significant. This is illustrated in Figure 1.
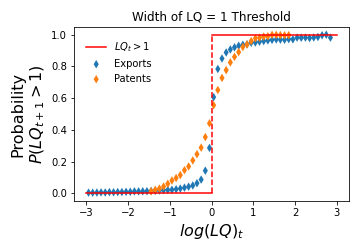
Figure 1: The discrete variable (red), and the probability that (blue). Plotted as a function of . In the extremes, both coincide, but near the threshold of , the latter provides a natural interpolation between the two values. Each dataset shows a certain transition width, suggesting that the scale of LQ is not unique for all datasets.
Interpretation and Implications
-
Probability Behavior: At very low and very high values (left and right ends of the plot in Figure 1), the probability approaches zero and one, respectively. It approaches 0.5 when .
-
Effective Distance: This probability acts as an interpolation between the 1 values, adding structure to the discrete threshold. It provides insight into the width of the transition from zero to one at .
Another interpretation of this interpolation is as an effective distance to the threshold. This is a key point we emphasize. Typically, there is uncertainty about whether a value, such as , is sufficiently close to . This approach allows us to specify that such a value corresponds to an 18% chance of in the dataset. We propose associating the chances of observing given with an effective length of the gap from 0.8 to 1.