Variance as a Function of Micro Moments
as a Function of Micro Moments ,
To advance further, we can use expressions for the moments of the distributions of log shocks into . By expressing the variance of the mean shown by a quantile part in terms of the moments of the micro distribution of shocks, , , we get:
The functions are derived from the moments of the distribution of micro deviations. This is further developed in the appendix for the ideal cases of log-normal and log-Laplace micro shocks.
Log-Normal Distribution
For log-normally distributed firm-level shocks, , we have:
In the limit of very small micro fluctuations:
Log-Laplace Distribution
For log-Laplace distributed firm-level shocks, , the variance is given by:
In the limit of small micro fluctuations:
These expressions for allow us to express in terms of the micro moments and . For the moment, the correct expression for a term like is still under development. However, by examining the equations, we expect it to be of the type: .
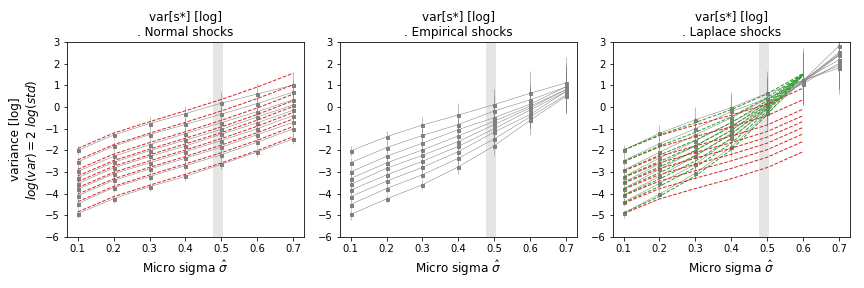
Figure: Variance of quantile levels as a function of the width of micro fluctuations , for various population sizes and . Log-normal (left), empirical (mid), and log-Laplace (right). The contribution from self variance follows the rule (red). In green, for the log-Laplace case, acknowledgment of comovements as a product of micromoments with population size . The magnitude of empirical is shown with a vertical gray band.
Nonlinearities and the Law of Large Numbers
The contribution shows cancellation of opposite shocks and convergence of the mean, as when averaging a time series showing additive deviations from a level. Both log-normal and log-Laplace shocks contain this dependence. However, these multiplicative micro shocks have additional higher-order terms that grow as micro fluctuations are turned on. These nonlinearities make multiplicative shocks different from additive Gaussian shocks and are particularly stronger if micro shocks are fat-tailed (log-Laplace).
In summary, nonlinearities contribute to variance, but the law of large numbers and its 'postponement' are distinct features. For small fluctuations applicable to any distribution of micro shocks if is small enough:
The expression for likely starts with a term of order . If we consider only the terms, we remain in the linear setting:
Without the comovement term, nonlinearities alone would increase the variance, although the law of large numbers would still apply. The breaking of this rule is due to comovements across agents, activated by nonlinearities that are absent in the additive Gaussian case, making comovement terms per agent times stronger than self-agent variance .